UML-04: DBSCAN and Density-Based Clustering

Master DBSCAN: The 'Island Finder' of machine learning. Learn how to map arbitrary cluster shapes, handle noise like an explorer, and tune epsilon without needing to guess 'K' upfront.
Master DBSCAN: The 'Island Finder' of machine learning. Learn how to map arbitrary cluster shapes, handle noise like an explorer, and tune epsilon without needing to guess 'K' upfront.

Master Hierarchical Clustering: the 'Digital Librarian' of machine learning. Understand how to organize data into nested trees, interpret dendrograms, and choose the right linkage method without needing to guess 'K' upfront.

Unlock the power of clustering. Master Lloyd's Algorithm from scratch, visualize the iterative 'Assignment-Update' loop, and solve the 'How many clusters?' dilemma with the Elbow Method.

Unlock the hidden potential of 'Dark Data'. Master Unsupervised Learning fundamentals, explore the 'Student vs. Explorer' analogy, and navigate the taxonomy of Clustering, Dimensionality Reduction, and Anomaly Detection.

A comparative tutorial on simulating necking instability in a tensile metal bar using COMSOL Multiphysics and Abaqus. We explore the modeling approaches, compare stress-strain behavior, and analyze the necking phenomenon from both platforms.

Linear plots often obscure the true physics of your simulation. Discover how logarithmic scales reveal hidden details in convergence plots, exponential trends, and field distributions—with real-world COMSOL examples on Solar Cells and Skin Effect.

A hands-on tutorial on simulating tensile fracture in copper using LAMMPS. We compare the simplified Morse potential with the accurate EAM potential and analyze stress-strain behavior during crack propagation.
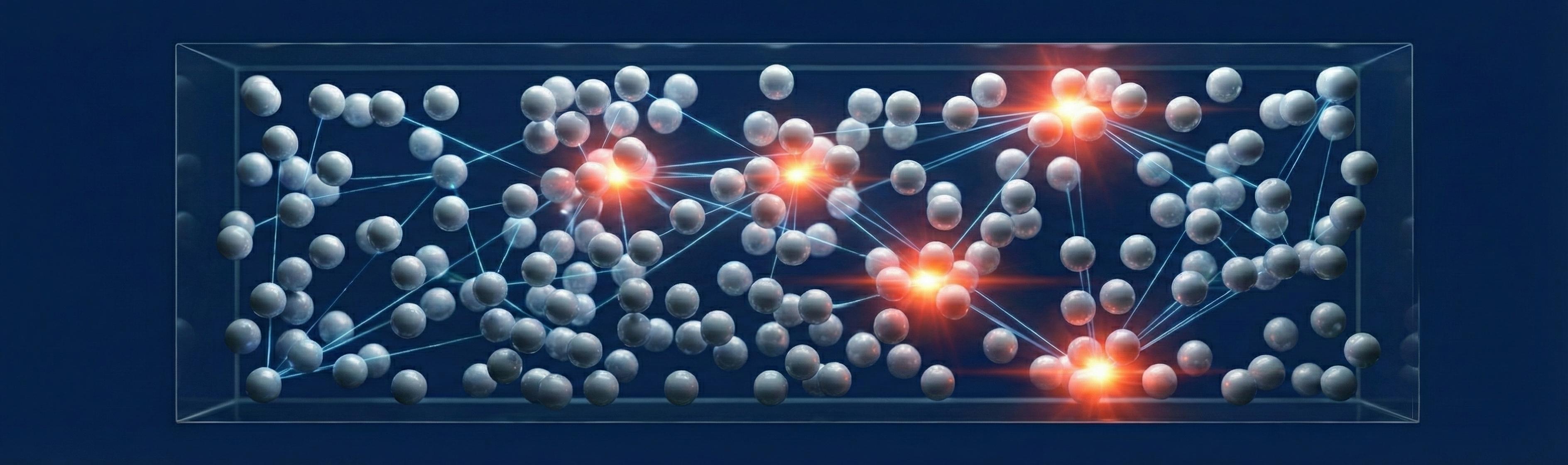
A deep dive into the 'Hello World' of Molecular Dynamics: simulating Lennard-Jones Argon. We derive the physics, build a scratch implementation in Python and Julia, and compare it with production-grade LAMMPS scripts.

Complete overview of the Supervised Machine Learning blog series: algorithm comparison, decision flowchart for model selection, and recommended next steps for your ML journey.

Master the Boosting paradigm: understand sequential ensemble learning, implement AdaBoost step-by-step with sample weight updates, and choose between Random Forest, AdaBoost, and Gradient Boosting.