ML-05: The Bias-Variance Tradeoff
Learning Objectives
- Understand bias and variance conceptually
- Identify underfitting and overfitting
- Learn strategies to balance model complexity
Theory
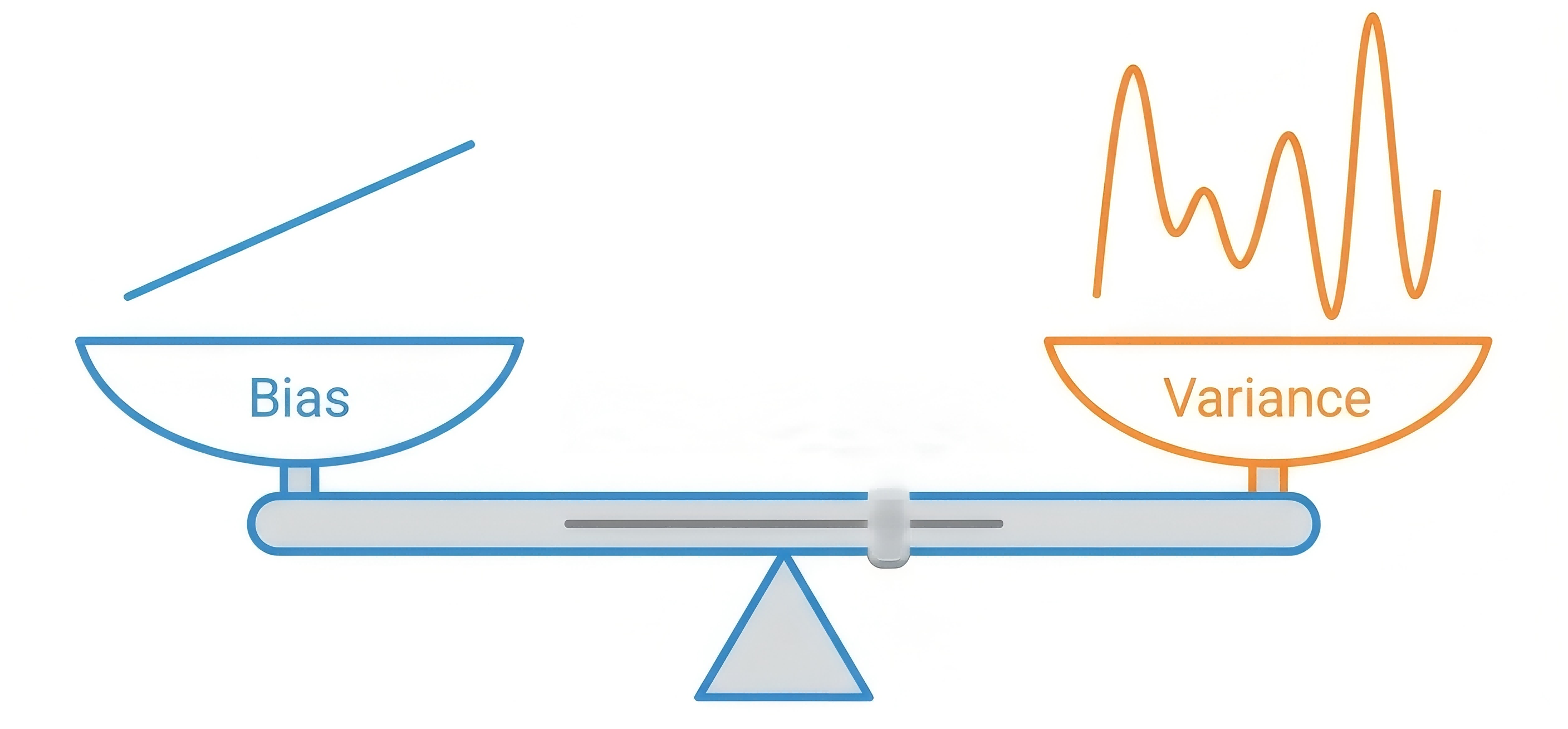
In the previous blog, the generalization bound showed that model complexity affects learning. But what exactly happens when a model is too simple or too complex? This is the bias-variance tradeoff — one of the most important concepts in machine learning.
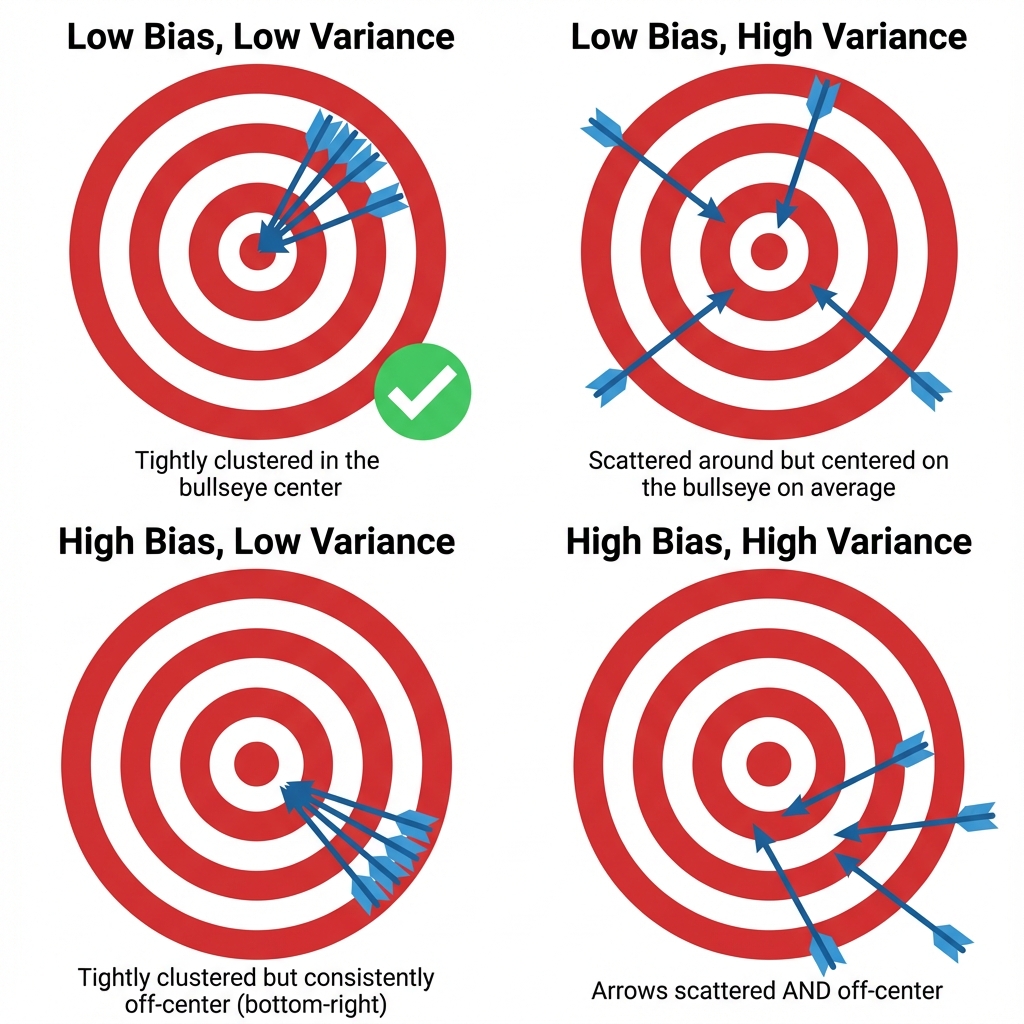
🎯 Archery Analogy: Imagine shooting arrows at a target:
- Bias = How far the average shot lands from the bullseye (systematic error)
- Variance = How spread out the shots are (inconsistency)
- Low bias + Low variance = Tightly clustered shots hitting the bullseye ✅
- High bias + Low variance = Tightly clustered but off-center
- Low bias + High variance = Centered on average but scattered everywhere
Expected Error Decomposition
$$E[(y - \hat{y})^2] = \text{Bias}^2 + \text{Variance} + \text{Irreducible Noise}$$
In plain English: The prediction error comes from three sources:
- Bias² — The model’s systematic tendency to miss the true value
- Variance — How much predictions fluctuate across different training sets
- Noise — Random errors in the data itself (irreducible)
💡 Why Bias² instead of Bias?
- Mathematical necessity: When expanding $E[(y - \hat{y})^2]$, the bias term naturally appears squared
- Non-negative guarantee: Bias can be positive (overestimate) or negative (underestimate), but error contributions must be ≥ 0
- Back to archery: If we didn’t square the bias, shots 5cm left and 5cm right would “cancel out” — clearly wrong for measuring error!
| Component | Cause | Fix |
|---|---|---|
| Bias | Model too simple | Increase complexity |
| Variance | Model too complex | Simplify or more data |
| Noise | Data randomness | Cannot fix |
Underfitting vs Overfitting
| Problem | Symptom | Solution |
|---|---|---|
| Underfitting | High train AND test error | More complex model |
| Overfitting | Low train, high test error | Simpler model, regularization, more data |
The following diagram shows how model complexity relates to bias and variance:
The Tradeoff Curve
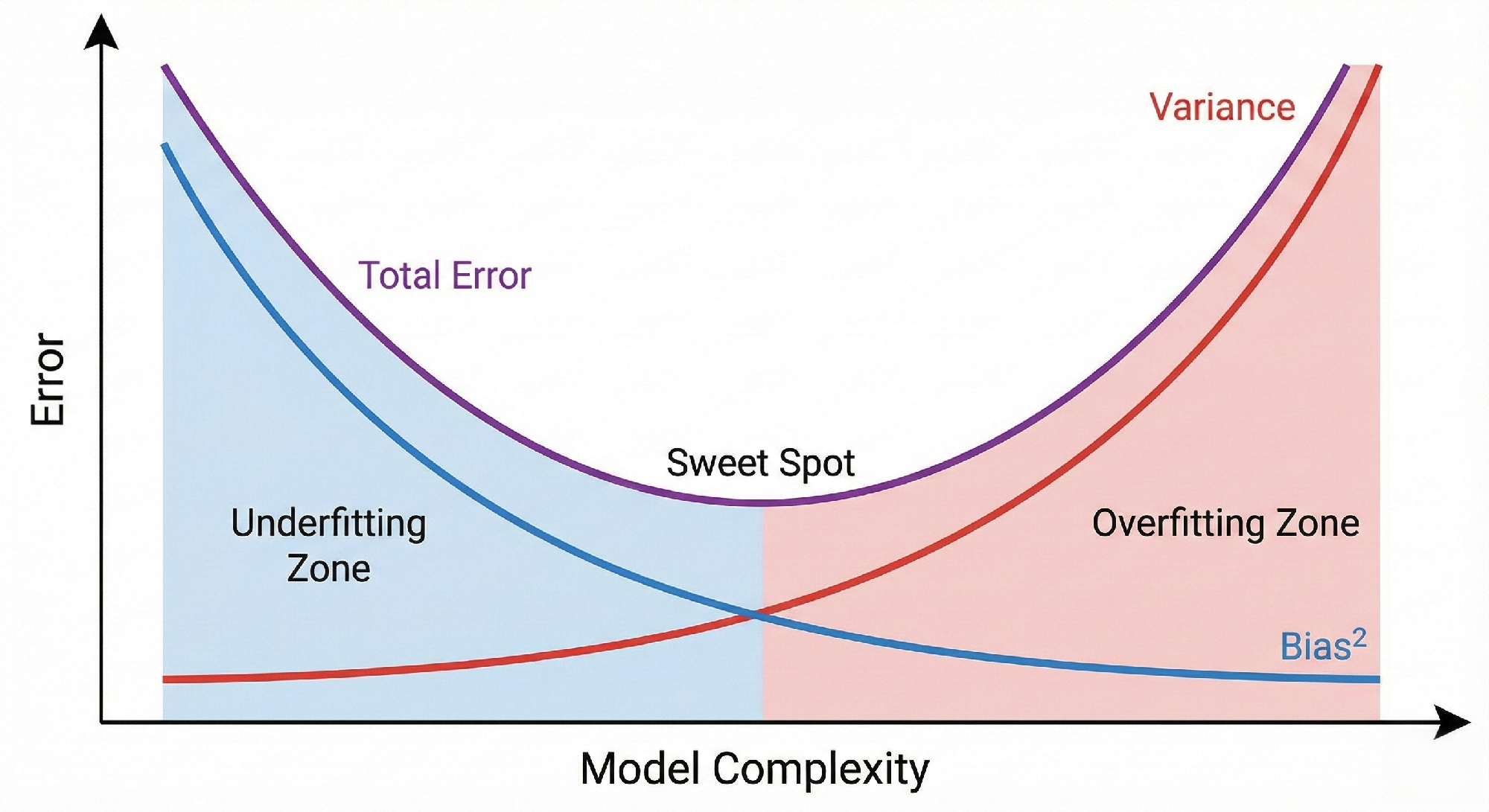
Reading the curve:
- Left side (low complexity): High bias dominates — model is too rigid to capture patterns
- Right side (high complexity): Variance dominates — model is too sensitive to noise
- Minimum point (sweet spot): Optimal complexity where total error is minimized
- Key insight: The curves move in opposite directions — reducing one tends to increase the other
Visual Example
Let’s see this tradeoff in action with polynomial regression on a sine wave:
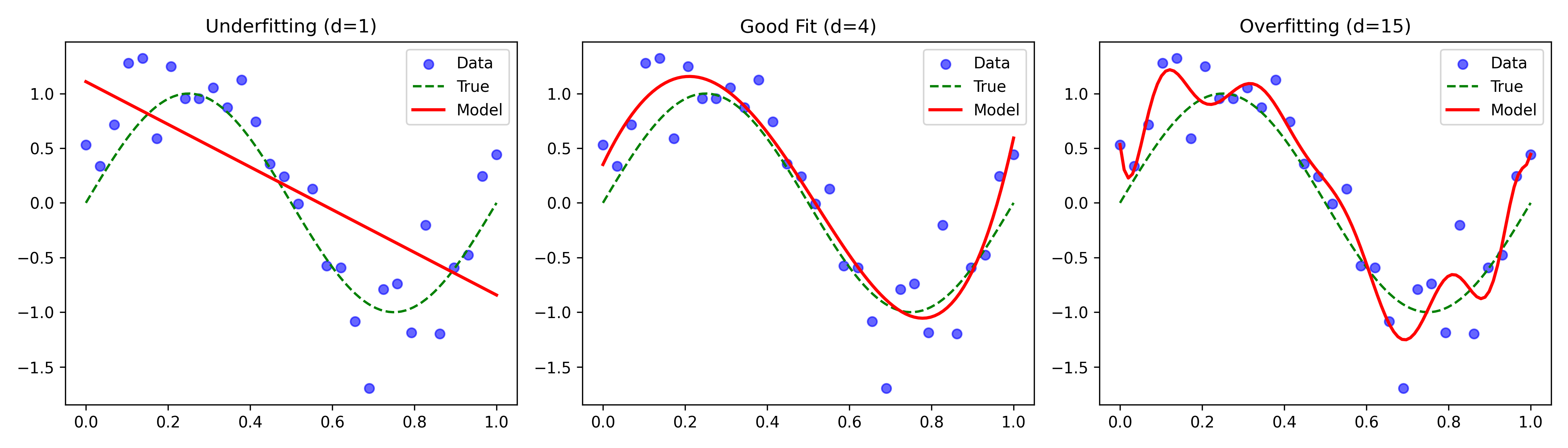
- Degree 1 (Linear): Underfitting — misses the curve
- Degree 4: Just right — captures pattern
- Degree 15: Overfitting — fits noise
Code Practice
Visualizing Bias-Variance
🐍 Python
| |
Computing Bias and Variance
🐍 Python
| |
Output:
Deep Dive
FAQ
Q1: How do I know if I’m underfitting or overfitting?
| Symptom | Diagnosis | Action |
|---|---|---|
| High train error, high test error | Underfitting | Increase model complexity |
| Low train error, high test error | Overfitting | Regularize, get more data, simplify |
| Low train error, low test error | Good fit! | Deploy with confidence |
Q2: Can I have both low bias and low variance?
Yes! With enough data, you can use complex models without overfitting. Ensemble methods (Blog 14-15) also achieve this by combining multiple models.
Q3: Which is worse: underfitting or overfitting?
Both are bad, but overfitting is more insidious — it looks good on training data, giving false confidence. Underfitting is at least honest about its limitations.
Summary
| Concept | Meaning |
|---|---|
| Bias | Error from oversimplified model |
| Variance | Sensitivity to training data fluctuations |
| Underfitting | High bias, model too simple |
| Overfitting | High variance, model too complex |
| Sweet Spot | Balance between bias and variance |
References
- Hastie, T. et al. “The Elements of Statistical Learning” - Chapter 7
- Abu-Mostafa, Y. “Learning From Data” - Chapter 4
- Stanford CS229: Regularization and Model Selection