UML-09: Association Rule Mining
Summary
Master Association Rules: The 'Symbiosis Scouter'. Learn how Apriori finds hidden partnerships (Support, Confidence, Lift) in your data ecosystem.
Learning Objectives
After reading this post, you will be able to:
- Understand the goal of association rule mining
- Know the key metrics: support, confidence, and lift
- Implement the Apriori algorithm for finding frequent itemsets
- Apply association rules to real-world market basket analysis
Theory
The Intuition: The Symbiosis Scouter
Imagine you are an ecologist exploring a vast Rainforest (The Dataset).
- Transaction: You examine small 10x10m patches of land.
- Itemset: The specific plants and animals you find in that patch.
- Association Rule: You notice a pattern: “Wherever I see a Clownfish, I see an Anemone.”
Association Rule Mining is about finding these Symbiotic Relationships in your data ecosystem, distinguishing true partnerships from random co-occurrences.
graph LR
A["🌿 Rainforest Patch\n(Transaction)"] --> B["🔍 Pattern Scout\n(Apriori)"]
B --> C["📋 Species Pairs\n(Frequent Itemsets)"]
C --> D["� Symbiosis Rule\n(Association Rules)"]
style B fill:#fff9c4
style D fill:#c8e6c9
Applications:
- 🛒 Nature (Market): Clownfish & Anemone (Bread & Butter).
- 🌐 Web: Visited Page A & Page B.
- 🏥 Medicine: Symptom X & Disease Y.
Key Concepts
Support (How Common?)
- Analogy: “How many patches have both a Clownfish AND an Anemone?”
- Formula: $Support(A) = \frac{\text{Transactions with A}}{\text{Total Transactions}}$
- Goal: Filter out rare species. If a pair only appears once in 1,000 patches, it’s not a general rule.
Confidence (How Reliable?)
- Analogy: “If I see a Clownfish, how sure am I that an Anemone is also there?”
- Formula: $Confidence(A \rightarrow B) = \frac{Support(A \cup B)}{Support(A)}$
- Goal: Measure the strength of the implication.
Lift (True Symbiosis vs. Coincidence)
- Analogy: “Do they need each other? Or are they just both everywhere (like Ants and Grass)?”
- Formula: $Lift(A \rightarrow B) = \frac{Confidence(A \rightarrow B)}{Support(B)}$
- Interpretation:
- Lift > 1 (Symbiosis): They appear together more than expected by chance. Positive correlation.
- Lift = 1 (Independence): No relationship. (e.g., “People who buy Bread also breathe Air” - useless).
- Lift < 1 (Competition): They avoid each other. Negative correlation.
The Apriori Algorithm
Apriori efficiently finds frequent itemsets using the apriori principle:
If an itemset is infrequent, all its supersets are also infrequent.
The Notion: “The Rotten Apple”
Think of a fruit basket.
- If one apple is rotten, the entire basket is considered “bad”.
- In Apriori: If {Beer} is rare (rotten), then {Beer, Diapers}, {Beer, Milk}, and {Beer, Anything} are also rare.
- Result: We don’t even bother checking the combinations. We throw the whole branch away.
This allows pruning of the search space.
graph LR
A["Start: All 1-itemsets"] --> B["Count support"]
B --> C["Prune infrequent"]
C --> D["Generate candidates"]
D --> E{"More candidates?"}
E -->|Yes| B
E -->|No| F["Frequent itemsets"]
style F fill:#c8e6c9
Algorithm Steps:
- Set minimum support threshold
- Find frequent 1-itemsets
- Generate candidate k+1 itemsets from frequent k-itemsets
- Prune candidates with infrequent subsets
- Count support and keep frequent ones
- Repeat until no new itemsets found
Code Practice
Creating Transaction Data
🐍 Python
| |
Output:
| |
Using mlxtend for Association Rules
🐍 Python
| |
Output:
| |
Generating Association Rules
🐍 Python
| |
Output:
| |
Visualizing Rules
🐍 Python
| |
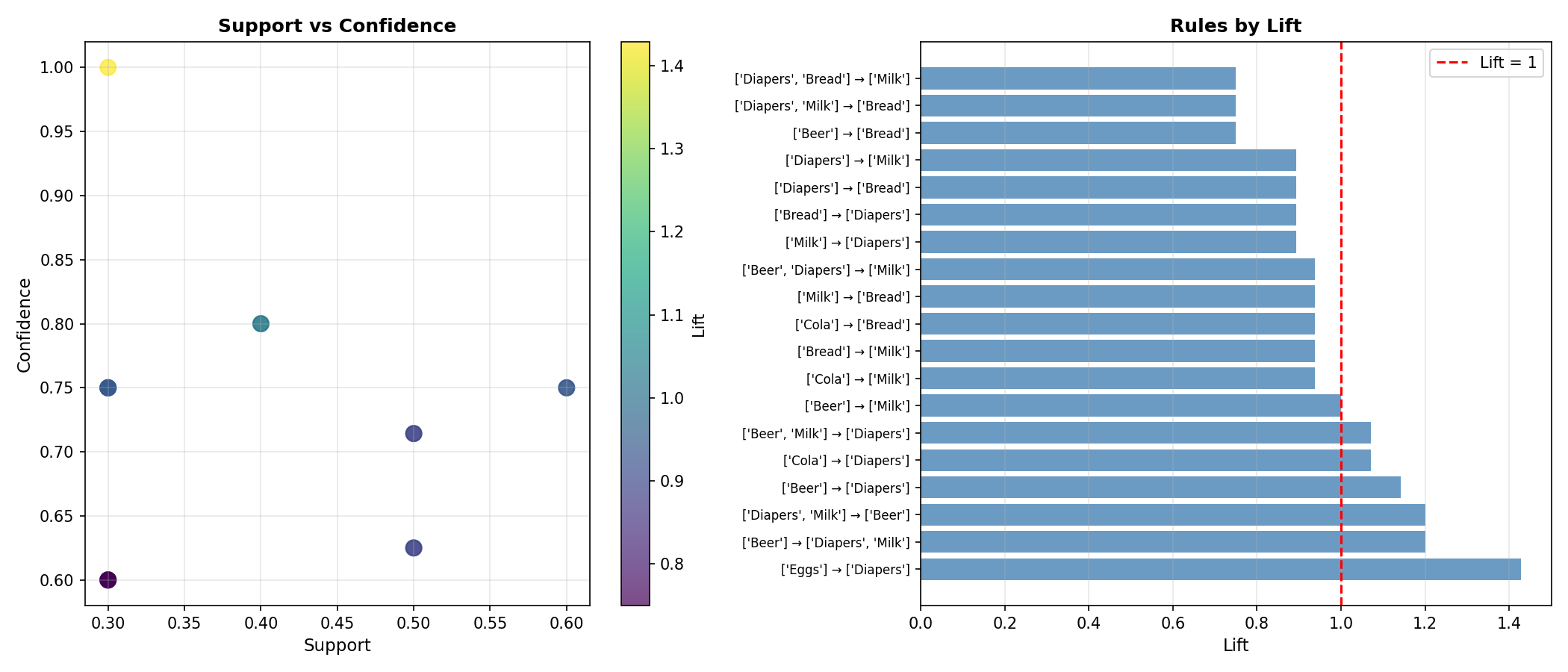
Deep Dive
Interpreting Metrics
| Metric | High Value Means | When to Use |
|---|---|---|
| Support | Common pattern | Filter rare items |
| Confidence | Rule is reliable | Predict behavior |
| Lift | Strong association | Find true patterns |
Pro tip: Focus on rules with high lift (> 1) — they indicate genuine associations, not just common items appearing together by chance.
The Popularity Trap (Confidence vs. Lift)
Why isn’t Confidence enough? Imagine a supermarket where everyone buys Water (Support = 90%).
- Rule: {Bread} -> {Water}
- Confidence: 90% (Wow! High reliability!)
- Reality: It’s useless. They would have bought Water anyway.
Lift exposes the truth:
- If Lift = 1, the rule is just a coincidence.
- Analogy: “Breathing Air” has 100% confidence with “Buying Bread”, but zero predictive value. Lift detects this independence.
Limitations and Challenges
Challenges in association rule mining:
- Combinatorial explosion: Many possible itemsets
- Threshold selection: min_support and min_confidence affect results
- Spurious patterns: High support doesn’t mean meaningful
- Scalability: Large transaction databases are expensive
Alternatives to Apriori
| Algorithm | Advantage |
|---|---|
| FP-Growth | Faster, uses tree structure |
| Eclat | Vertical data format, efficient |
| Spark MLlib | Distributed, big data |
Summary
| Concept | Key Points |
|---|---|
| Association Rules | Find patterns like “If A, then B” |
| Support | Frequency of itemset |
| Confidence | How often rule is true |
| Lift | Strength of association (> 1 = positive) |
| Apriori | Prunes search space using subset property |
References
- Agrawal, R. & Srikant, R. (1994). “Fast Algorithms for Mining Association Rules”
- mlxtend Documentation
- “Data Mining: Concepts and Techniques” by Han, Kamber & Pei - Chapter 6