ML-08: Logistic Regression Basics
Learning Objectives
- Understand why logistic regression is needed for classification
- Master the sigmoid function
- Derive cross-entropy loss
- Handle multi-class problems
Theory
From Linear to Logistic
Classification tasks differ fundamentally from regression. Consider spam detection: given email features, the goal is to predict whether an email is spam (1) or not spam (0).
The Problem with Linear Regression:
If linear regression is applied directly: $$\hat{y} = \boldsymbol{w}^T \boldsymbol{x}$$
The output can be any real number: $-\infty$ to $+\infty$. But for classification:
- A probability between 0 and 1 is needed
- A clear decision rule is required (e.g., if probability > 0.5, predict class 1)
The Solution: A function that “squashes” any real number into the (0, 1) range solves this problem — enter the sigmoid function.
Sigmoid Function
$$\sigma(z) = \frac{1}{1 + e^{-z}}$$
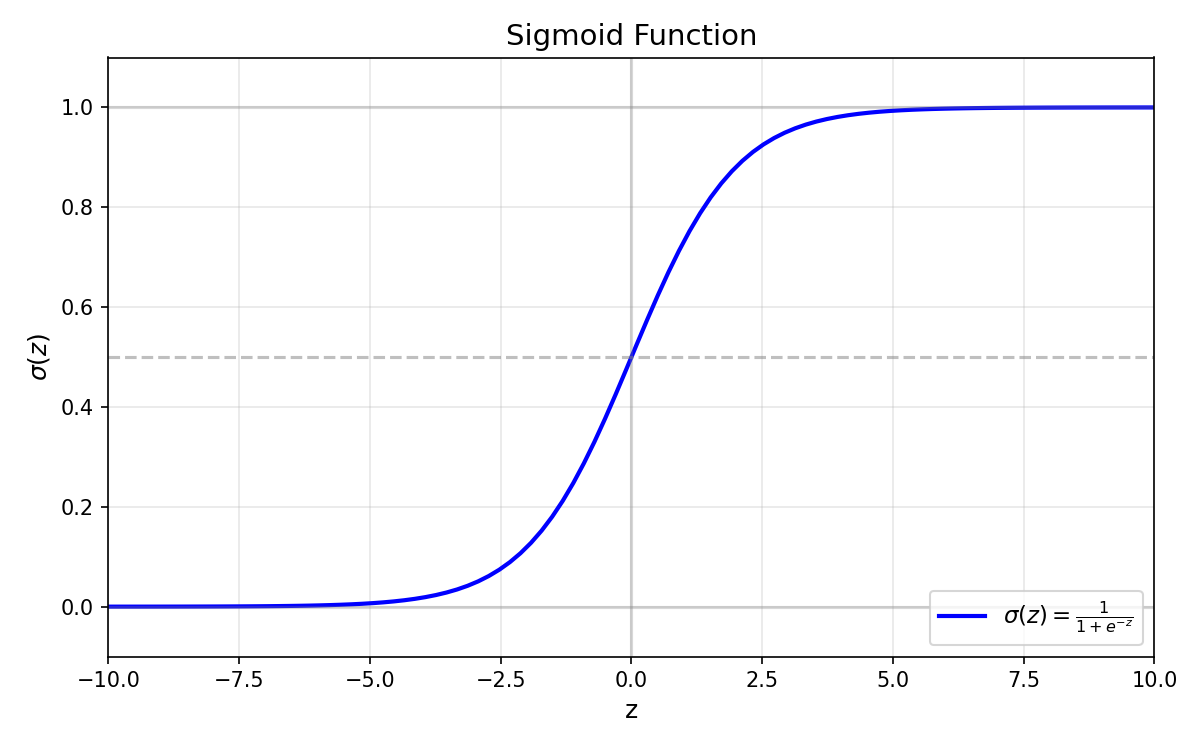
Key Properties:
| Property | Value | Interpretation |
|---|---|---|
| Range | $(0, 1)$ | Always outputs a valid probability |
| $\sigma(0)$ | $0.5$ | Neutral point — equal chance for both classes |
| $\sigma(\infty)$ | $1$ | Very positive input → high confidence for class 1 |
| $\sigma(-\infty)$ | $0$ | Very negative input → high confidence for class 0 |
| Derivative | $\sigma’(z) = \sigma(z)(1-\sigma(z))$ | Smooth gradient, maximum at $z=0$ |
Why Sigmoid?
- Probabilistic interpretation: Output can be interpreted as $P(y=1|x)$
- Smooth gradients: Unlike step functions, sigmoid is differentiable everywhere — essential for gradient-based optimization
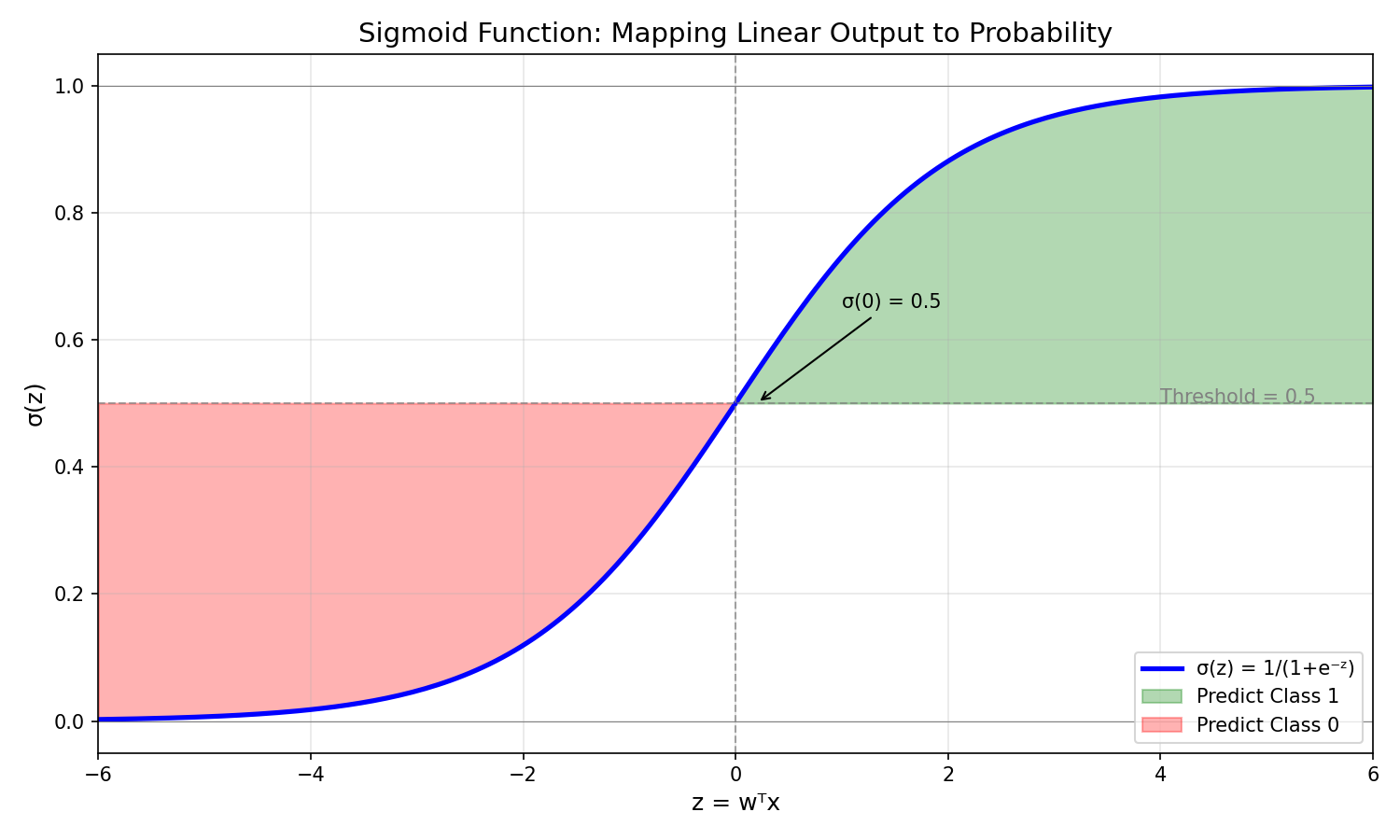
- Natural decision boundary: The 0.5 threshold corresponds to $\boldsymbol{w}^T \boldsymbol{x} = 0$
Logistic Regression Model
With the sigmoid function in hand, the logistic regression model combines linear combination with probability transformation:
$$P(y=1|\boldsymbol{x}) = \sigma(\boldsymbol{w}^T \boldsymbol{x}) = \frac{1}{1 + e^{-\boldsymbol{w}^T \boldsymbol{x}}}$$
Decision Rule:
- If $P(y=1|\boldsymbol{x}) \geq 0.5$ → predict class 1
- If $P(y=1|\boldsymbol{x}) < 0.5$ → predict class 0
This is equivalent to:
- If $\boldsymbol{w}^T \boldsymbol{x} \geq 0$ → predict class 1
- If $\boldsymbol{w}^T \boldsymbol{x} < 0$ → predict class 0
The equation $\boldsymbol{w}^T \boldsymbol{x} = 0$ defines the decision boundary — a hyperplane that separates the two classes.
Cross-Entropy Loss
To train the model, a loss function that measures prediction quality is needed.
Why not Mean Squared Error (MSE)? For probability outputs, MSE produces flat gradients near 0 and 1, making learning slow. Cross-entropy provides stronger gradients for wrong predictions, enabling faster and more effective learning.
Derivation from Maximum Likelihood:
For a single sample with true label $y$ and predicted probability $\hat{y}$:
$$P(y|\boldsymbol{x}) = \hat{y}^y \cdot (1-\hat{y})^{(1-y)}$$
Taking the negative log (to convert maximization to minimization):
$$-\log P(y|\boldsymbol{x}) = -[y \log(\hat{y}) + (1-y)\log(1-\hat{y})]$$
For $N$ samples, the binary cross-entropy loss is:
$$L = -\frac{1}{N}\sum_{i=1}^{N}[y_i \log(\hat{y}_i) + (1-y_i)\log(1-\hat{y}_i)]$$
Intuition:
- When $y=1$: Loss = $-\log(\hat{y})$ → penalizes low predicted probability
- When $y=0$: Loss = $-\log(1-\hat{y})$ → penalizes high predicted probability
| True $y$ | Predicted $\hat{y}$ | Loss | Interpretation |
|---|---|---|---|
| 1 | 0.9 | 0.105 | Good prediction, low loss |
| 1 | 0.1 | 2.303 | Bad prediction, high loss |
| 0 | 0.1 | 0.105 | Good prediction, low loss |
| 0 | 0.9 | 2.303 | Bad prediction, high loss |
Gradient Derivation
To update the weights during training, the gradient of the loss with respect to weights must be computed. Remarkably, the math simplifies to:
$$\frac{\partial L}{\partial \boldsymbol{w}} = \frac{1}{N} \sum_{i=1}^{N} (\hat{y}_i - y_i) \boldsymbol{x}_i$$
This elegant result — simply the prediction error multiplied by the input — makes implementation straightforward and computationally efficient.
Multi-Class: One-vs-Rest (OvR)
Logistic regression naturally handles binary classification. For problems with $K > 2$ classes, the One-vs-Rest (OvR) strategy trains $K$ separate binary classifiers:
| Classifier | Positive Class | Negative Class |
|---|---|---|
| Classifier 1 | Class 0 | Classes 1, 2, …, K-1 |
| Classifier 2 | Class 1 | Classes 0, 2, …, K-1 |
| … | … | … |
| Classifier K | Class K-1 | Classes 0, 1, …, K-2 |
Prediction: For a new sample, run all $K$ classifiers and choose the class with highest probability.
Alternative: Softmax (Multinomial)
Rather than training $K$ separate classifiers, a more unified approach uses a single model with softmax activation:
$$P(y=k \vert \mathbf{x}) = \frac{e^{\mathbf{w}_k^T \mathbf{x}}}{\sum_{j=1}^{K} e^{\mathbf{w}_j^T \mathbf{x}}}$$
This ensures all class probabilities sum to 1.
Code Practice
This section applies the theoretical concepts to real data, starting with the classic Iris dataset and progressing through sigmoid visualization, custom implementation, and sklearn usage.
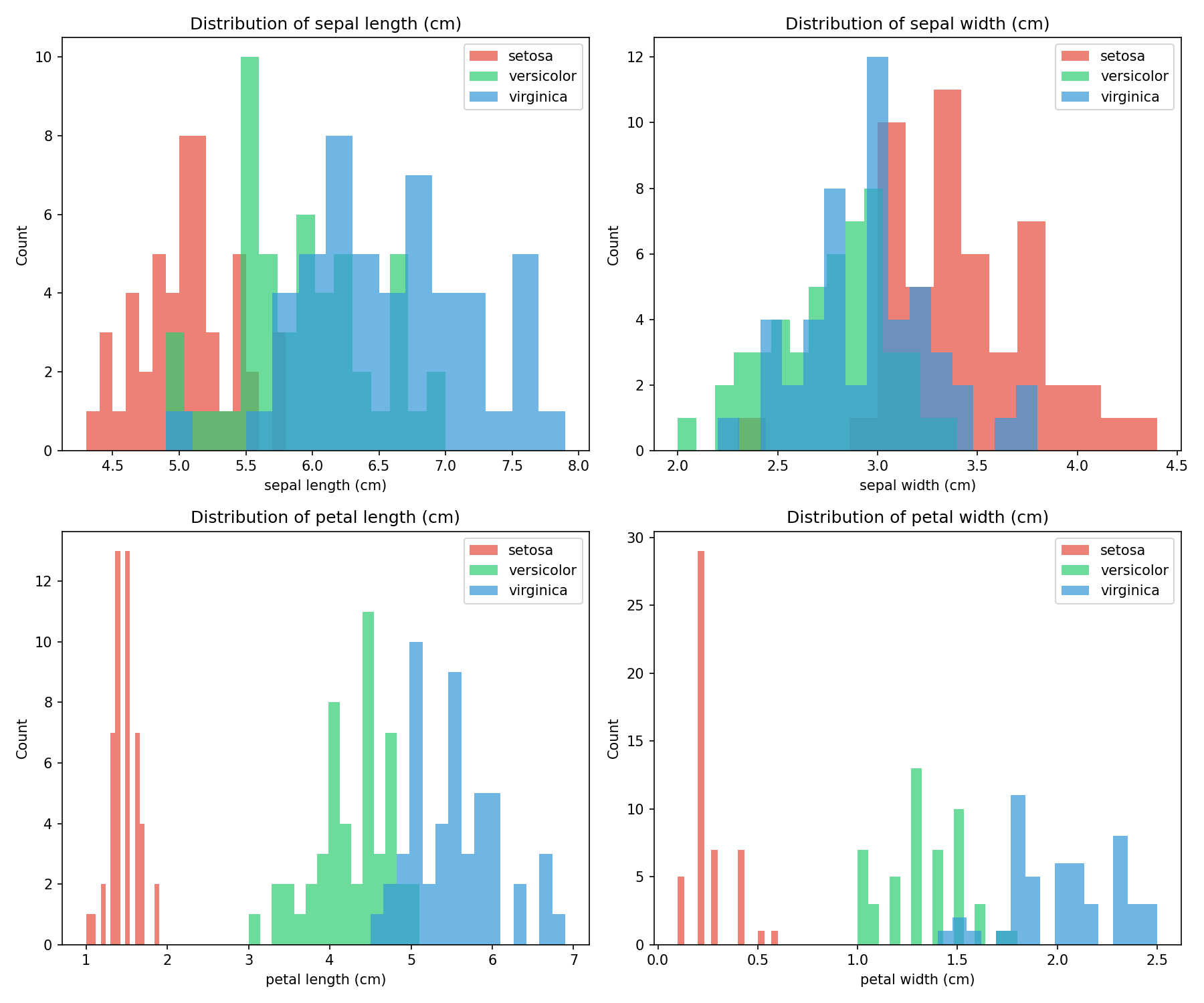
The Iris Dataset
The Iris dataset serves as a classic machine learning benchmark, containing measurements from 150 iris flowers across 3 species:
- Setosa (class 0)
- Versicolor (class 1)
- Virginica (class 2)
Each flower has 4 features: sepal length, sepal width, petal length, and petal width (all in cm).
🐍 Python - Dataset Visualization
| |
Output:
| |
🐍 Python - Feature Distribution
| |
Sigmoid Visualization
🐍 Python
| |
Logistic Regression from Scratch
Translating the mathematical formulas into code reveals the simplicity of logistic regression. The following implementation covers the complete training loop:
🐍 Python
| |
Output:
sklearn Example
🐍 Python
| |
Outputs:
Multi-Class Classification
🐍 Python
| |
Output:
| |
Decision Boundary Visualization
The true power of logistic regression becomes visible when plotting the decision boundary — the line where P(Class 1) = 0.5. This visualization shows how the model separates two classes in 2D feature space:
🐍 Python
| |
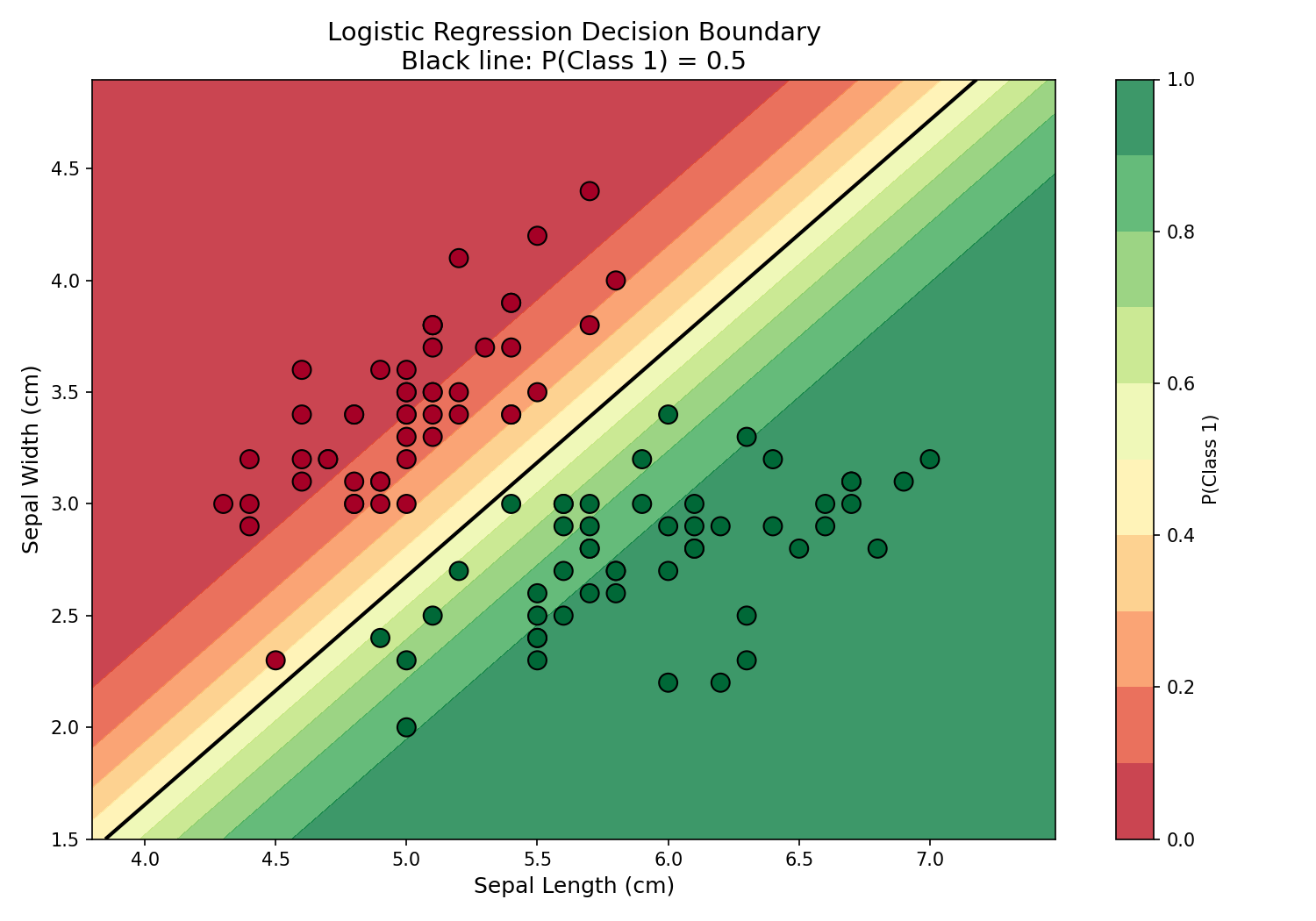
Deep Dive
This section addresses common questions and practical considerations when applying logistic regression.
Q1: Logistic regression vs. Perceptron?
| Aspect | Perceptron | Logistic Regression |
|---|---|---|
| Output | Hard label (+1/-1) | Probability (0-1) |
| Loss | Misclassification | Cross-entropy |
| Gradient | Discontinuous | Smooth |
| Convergence | May not converge | Always converges |
Key insight: Logistic regression is preferred when probability estimates are needed, or when a smooth optimization landscape is desired.
Q2: What if classes are imbalanced?
Imbalanced datasets (e.g., 95% class 0, 5% class 1) can bias the model toward the majority class.
Solutions:
- Use
class_weight='balanced'in sklearn — automatically adjusts weights inversely proportional to class frequencies - Adjust the decision threshold — instead of 0.5, use a threshold that optimizes F1-score or precision/recall
- Resample the data — oversample minority class (SMOTE) or undersample majority class
- Use appropriate metrics — precision, recall, F1-score, or AUC-ROC instead of accuracy
Q3: Why cross-entropy and not squared error?
Cross-entropy has nicer gradients for probability outputs.
| Loss Function | Gradient when $\hat{y}=0.01$, $y=1$ | Learning Speed |
|---|---|---|
| Cross-entropy | Large (≈99) | Fast correction |
| Squared error | Small (≈0.02) | Slow correction |
Squared error can have very flat gradients near 0 and 1, making learning slow and potentially causing the model to get stuck.
Q4: Do features need to be scaled?
Yes, feature scaling is recommended for logistic regression, especially when using gradient descent.
| Feature Scaling | Effect |
|---|---|
| Not scaled | Features with larger values dominate; slow convergence |
| Standardized (z-score) | Equal contribution from all features; faster convergence |
Q5: How to prevent overfitting?
Logistic regression can overfit, especially with many features or when features are correlated.
Regularization:
- L2 (Ridge): $L + \lambda \sum w_j^2$ — shrinks all weights toward zero
- L1 (Lasso): $L + \lambda \sum |w_j|$ — encourages sparsity (some weights become exactly zero)
Q6: Logistic regression vs. other classifiers?
| Classifier | Strengths | Weaknesses |
|---|---|---|
| Logistic Regression | Interpretable, fast, probability outputs | Linear decision boundary only |
| SVM | Works well in high dimensions | No native probability output |
| Decision Tree | Non-linear, interpretable | Prone to overfitting |
| Neural Network | Highly flexible | Needs lots of data, less interpretable |
Summary
Key Formulas
| Concept | Formula |
|---|---|
| Sigmoid | $\sigma(z) = \frac{1}{1+e^{-z}}$ |
| Model | $P(y=1|\boldsymbol{x}) = \sigma(\boldsymbol{w}^T \boldsymbol{x})$ |
| Cross-Entropy | $L = -\frac{1}{N}\sum[y\log(\hat{y}) + (1-y)\log(1-\hat{y})]$ |
| Gradient | $\nabla L = \frac{1}{N} X^T (\hat{y} - y)$ |
Key Takeaways
- Sigmoid transforms linear output to probability — essential for classification tasks
- Cross-entropy loss provides better gradients than MSE for probability outputs
- Decision boundary is a hyperplane defined by $\boldsymbol{w}^T \boldsymbol{x} = 0$
- Multi-class can be handled via OvR (K binary classifiers) or Softmax
- Regularization (L1/L2) prevents overfitting and improves generalization
When to Use Logistic Regression
| ✅ Use When | ❌ Avoid When |
|---|---|
| Need interpretable model | Non-linear decision boundary required |
| Need probability outputs | Complex feature interactions exist |
| Linear separability expected | Very high-dimensional sparse data |
| Fast training/inference needed | Deep feature learning is beneficial |
References
- Bishop, C. “Pattern Recognition and Machine Learning” - Chapter 4
- sklearn Logistic Regression
- Cox, D.R. (1958). “The Regression Analysis of Binary Sequences”